
안녕하세요!
withMe 서비스의 프론트엔드는 NEXT.JS 프레임워크를 사용하여 웹 페이지를 개발하고 있습니다.
이번 글에서는 무한 스크롤에서 대량의 데이터를 렌더링할 때 발생하는 성능 문제를 React Profiler를 통해 분석하고, 이를 개선한 경험을 공유하고자 합니다.
많은 관심과 피드백 부탁드립니다. 🙏
서론
Facebook, Instagram, Twitter 등의 피드에서 새로운 게시물이 무한 스크롤 방식으로 계속 로드되는 경험을 한 번쯤 해보셨을 겁니다. withMe는 본인의 워크스페이스를 무한 스크롤 형식으로 제공하여, 다양한 디바이스에서도 반응형으로 원활하게 볼 수 있도록 구현했습니다.
만약 10만 개 이상의 데이터가 있을 경우, 어떤 일이 발생할까요?
페이징 처리를 한다면 페이지당 표시되는 데이터의 개수만큼 보여지겠지만, 10만 개의 데이터라면 그만큼의 데이터를 모두 로드해야 합니다.
이 과정에서 10만 개의 데이터를 모두 리렌더링하는 문제가 발생했고, 그로 인해 성능 저하가 일어났습니다.
이 문제를 해결할 수 있는 방법은 2가지가 있습니다.
- 가상 리스트(virtual list)
- 메모이제이션(Memoization)
저는 메모이제이션을 통해 렌더링을 최적화했지만, 추후에는 가상 리스트를 사용하여 추가적으로 개선할 예정입니다.
Next에서 무한 스크롤
앞서 Next에서 무한 스크롤 구현하는 법을 간략히 설명하겠습니다.
초기 데이터를 서버에서 미리 prefetch하여 가져온 후, 이후에는 클라이언트에서 데이터를 렌더링하도록 하여 UX를 개선했습니다.
즉, 첫 로딩 시 데이터 패칭이 없기 때문에 더 빠르게 로딩됩니다.
코드로 살펴보겠습니다.
const client = new QueryClient({
defaultOptions: {
queries: {
refetchOnWindowFocus: false,
retryOnMount: true,
refetchOnReconnect: false,
retry: false,
},
},
}),
export default function Layout({ children }: Props) {
return (
<div className="container-wrapper">
<QueryClientProvider client={client}>
{children}
<ReactQueryDevtools initialIsOpen={process.env.NEXT_PUBLIC_MODE === 'local'} />
</QueryClientProvider>
</div>
);
}
먼저 React-Query를 사용할 세팅을 해야합니다.
앱의 최상위에서 QueryClientProvider로 감싸주어 하위 모든 컴포넌트들이 QueryClient에 접근 가능하도록 해줍니다.
QueryClient는 데이터를 패칭하고 캐싱하고, 리패칭하는 역할을 합니다.
하위 모든 컴포넌트들이 해당 queryClient에 접근할 수 있게 되어 각 컴포넌트가 데이터를 패칭하거나 캐싱된 데이터를 사용하더라도 일관된 상태를 유지할 수 있습니다.
이제 QueryClient로 데이터를 받아와 캐싱해볼까요?
export async function getPostWorkSpace({ pageParam = { page: 0, cursor: null } }: { pageParam?: PageParam }) {
try {
const response = await axios.get(`${process.env.NEXT_PUBLIC_BACKEND_URL}${API_URL.WORKSPACE_O}`, {
headers: {
'Cache-Control': 'no-store',
},
params: {
cursor: pageParam.cursor,
page: pageParam.page,
size: 10,
},
});
return {
data: response.data,
};
} catch (error) {
console.log(error);
throw new Error('Failed to fetch data: ' + error);
}
}
export default async function Home() {
const queryClient: QueryClient = new QueryClient();
await queryClient.prefetchInfiniteQuery({
queryKey: ['workspace'],
queryFn: ({ pageParam = { page: 0, cursor: null } }: { pageParam: PageParam }) => getPostWorkSpace({ pageParam }),
initialPageParam: { page: 0, cursor: null } as PageParam,
});
const dehydratedState = dehydrate(queryClient);
return (
<div className="responsive_container">
<HydrationBoundary state={dehydratedState}>
<main className="w-full ">
<SnakBarContainer />
</main>
</HydrationBoundary>
<Footer />
</div>
);
}
- prefetchInfiniteQuery → React-Query의 기능으로, 데이터를 서버에서 미리 패칭합니다.
- queryKey → [workspace]는 해당 쿼리의 키를 설정하고, 이를 통해 React-Query가 데이터를 추적할 수 있게 됩니다.
- queryFn → 데이터를 패칭하는 함수를 전달하며, getPostWorkSpace는 위에서 설명한 대로 데이터를 실제로 가져오는 함수입니다.
- initialPageParam → 데이터 요청 시 초기 페이지와 커서를 설정합니다.
서버에서 패칭한 데이터를 클라이언트에서 동기화를 해주어야 합니다.
그래서 dehydrate로 패칭한 데이터를 직렬화 합니다.
결국 이 직렬화한 값을 토대로 원복하는 과정을 가집니다.
hydrationBoundary는 이 직렬화한 값을 복원하여 클라이언트에서 React-Query가 작동하게 하고, React 컴포넌트로 변환하고 인터렉티브한 UI로 변환하는 과정을 가집니다.
이제 클라이언트에서 사용자가 스크롤을 내리면 다음 페이지의 데이터를 불러오는 기능을 구현해야 합니다.
/* eslint-disable @typescript-eslint/no-unused-vars */
'use client';
import { useRef, useEffect } from 'react';
import { useInfiniteQuery } from '@tanstack/react-query';
import { AutoSizer, Grid } from 'react-virtualized';
import { getPostWorkSpace } from '../page';
import { ApiResponse, RootResponse, WorkspaceContent } from '../model/workSpaceItem'; // 타입 파일 경로에 맞게 수정
import UserWorkSpace from './UserWorkSpace';
import { WorkspaceStateProvider } from '../../_components/WorkspaceInfoProvider';
interface PageParam {
page: number;
cursor: string | null;
}
export default function WorkSpaceContainer() {
const {
data: apiResponse,
fetchNextPage,
hasNextPage,
} = useInfiniteQuery<RootResponse, Error, ApiResponse, ['workspace'], PageParam>({
queryKey: ['workspace'],
queryFn: ({ pageParam = { page: 0, cursor: null } }) => getPostWorkSpace({ pageParam }),
getNextPageParam: (lastPage, allPages) => {
const isLastPage = lastPage.data?.data?.last;
return isLastPage ? null : { page: allPages.length, cursor: lastPage.data.timestamp || null };
},
initialPageParam: { page: 0, cursor: null },
enabled: false,
});
const workspaces: WorkspaceContent[] = apiResponse?.pages.flatMap((page) => page.data.data.content) || [];
const observerRef = useRef<HTMLDivElement | null>(null);
useEffect(() => {
const observer = new IntersectionObserver(
(entries) => {
if (entries[0].isIntersecting && hasNextPage) {
fetchNextPage();
}
},
{ threshold: 1.0 }, // 요소가 완전히 보일 때만 트리거
);
const currentObserverRef = observerRef.current;
if (currentObserverRef) {
observer.observe(currentObserverRef);
}
return () => {
if (currentObserverRef) {
observer.unobserve(currentObserverRef);
}
};
}, [fetchNextPage, hasNextPage]);
if (!workspaces) {
return <div></div>;
}
return (
<>
{workspaces.length === 0 ? (
<div>
<span className="text-[30px]" style={{ fontFamily: 'SamsungOneKorean-400' }}>
Add 버튼을 클릭하여
</span>
<p className="text-[30px]">레포지토리를 추가해주세요.</p>
</div>
) : (
workspaces.map((workspace) => (
<UserWorkSpace key={`${workspace.id}-user-workspace`} workspace={workspace} />
))
)}
{hasNextPage && <div ref={observerRef} style={{ height: '20px', backgroundColor: 'transparent' }} />}
</>
);
}
이 코드는 클라이언트에서 작동하는 코드입니다.
초기 데이터는 서버에서 미리 패치했다면 그 이후 클라이언트에서 무한 스크롤로 데이터를 패치하도록 해야합니다.
저는 IntersectionObserver를 통해 무한 스크롤을 구현했습니다.
IntersectionObserver는 관찰 중인 요소가 뷰포트와 교차하는지 감지할 수 있는 API입니다.
observerRef 요소가 화면에 100% 보일 때, IntersectionObserver의 콜백 함수가 트리거됩니다. 이 시점에 다음 페이지 데이터를 패치하면 됩니다.
이렇게 Next에서 무한 스크롤을 구현할 수 있습니다.
대량의 데이터일 때 렌더링 최적화
소량에 데이터일 경우 렌더링하는 것은 큰 문제가 되지 않습니다.
대량에 데이터일 경우 심각한 성능 저하를 야기할 수 있습니다.
react-query 데이터를 패치할 때마다 해당 컴포넌트는 리렌더링이 되기 때문에 Item들 또한 렌더링이 됩니다.
만약 10만 개, 100만 개의 아이템을 이미지와 함께 재렌더링한다면, 성능에 큰 영향을 미칠 수 있습니다.
저는 이러한 문제를 React Profiler를 통해 분석하고 React.memo를 통해 메모이제이션하여 최적화를 하였습니다.
코드를 통해 살표봅시다.
'use client';
const UserWorkSpace: React.FC<UserWorkSpaceProps> = ({ workspace }) => {
//..생략
return (
<div>
//... 내용
</div>
);
};
export default React.memo(UserWorkSpace);
Item 컴포넌트를 React.memo로 설정해주었습니다.
(33개 데이터 - 최적화 전)
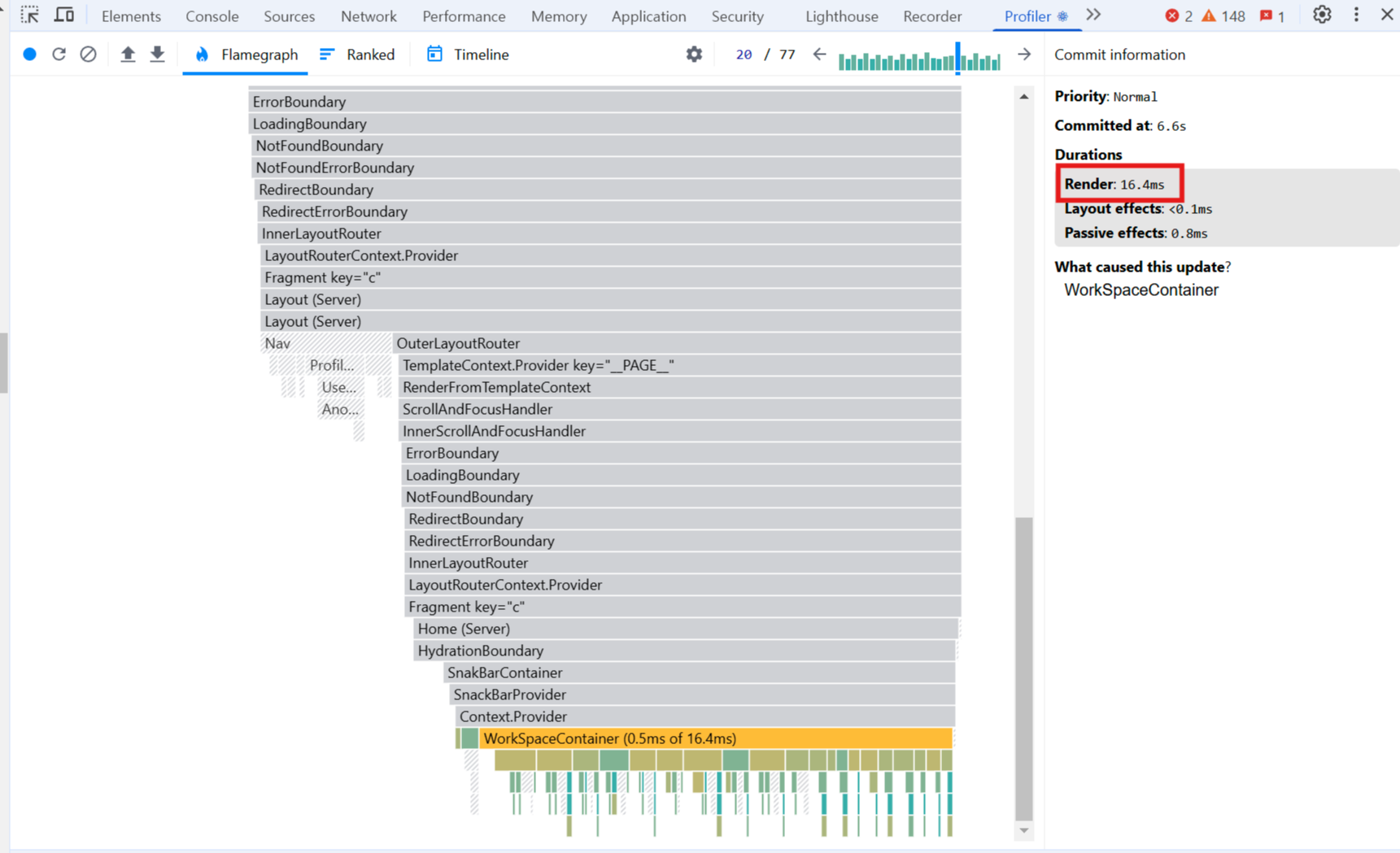
페이징 처리할 때마다 모든 Item들을 전부 렌더링 하고 있습니다.
(33개 데이터 - 최적화 후)
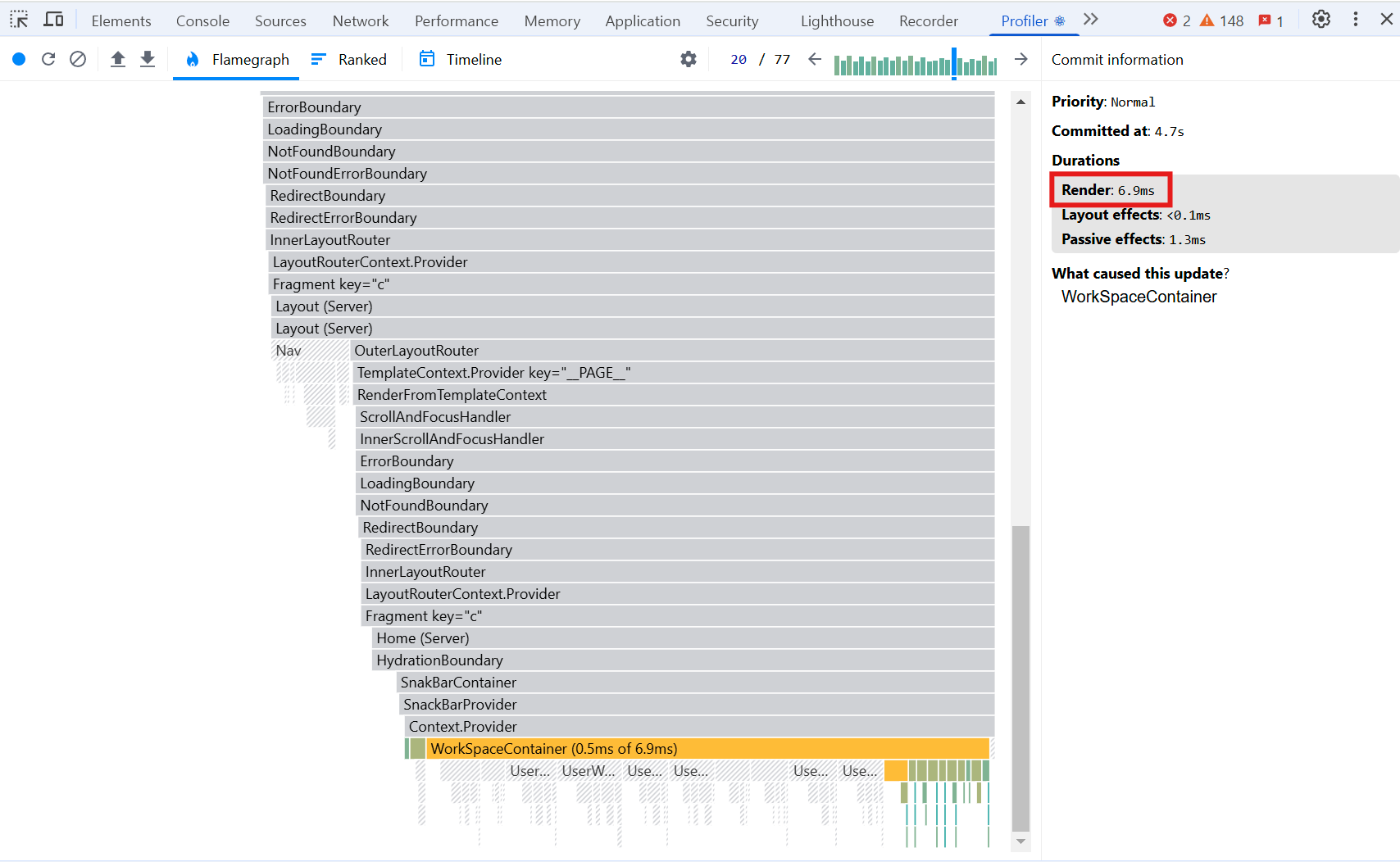
React.memo를 사용하여 이전 아이템들은 메모이제이션 처리되어 있습니다.
반면, 새롭게 불러온 데이터만 렌더링되고 있습니다. 재랜더링 될 때마다 10개의 아이템만 렌더링되므로 성능을 최적화할 수 있습니다.
예를 들어, 33개의 데이터에 대해 2번의 페이징 처리가 발생하는데, 이때 렌더링 시간이 (16.4ms → 6.9ms)로 줄어듭니다.
만약 10만 개와 같은 대량의 데이터를 처리할 경우, 성능 차이가 훨씬 더 크게 체감될 것입니다.
가상 리스트
메모이제이션은 이전 계산 결과를 저장하는 방식이기 때문에 메모리를 사용하게 됩니다. 따라서 메모리 측면에서도 배제할 수 없는 문제점이 있을 수 있습니다.
그래서 가상 리스트를 소개하려 합니다.

가상화 목록은 전체 데이터를 모두 렌더링하는 대신, 유저 스크롤에 따라 현재 보이는 데이터만을 렌더링 하는 방법입니다.
가상 리스트를 사용하면 필요한 부분만 렌더링되며, 메모리 측면에서도 메모이제이션 기법보다 훨씬 적은 자원을 사용할 수 있습니다.
대표적인 라이브러리로는
- react-virtualized
- react-window
가 있습니다.
이로써 Next.js에서 무한 스크롤 구현과 Profiler를 통한 성능 문제 감지, 그리고 React.memo를 활용한 최적화 과정을 마치겠습니다.
감사합니다.
'project > withMe' 카테고리의 다른 글
| Font 최적화로 웹 페이지 성능 향상하기 (0) | 2025.03.11 |
|---|---|
| SSG와 ISR을 활용한 캐싱 및 Redis를 이용한 동기화 (0) | 2025.03.02 |
| CSS 애니메이션 성능 개선 방법 (0) | 2025.02.28 |
| 이미지 스프라이트로 로딩 시간 단축하기 (0) | 2025.02.27 |
| NEXT/IMAGE를 활용한 웹 성능 최적화 (0) | 2025.02.27 |



